SitePal has always supported what we refer to as “Dynamic TTS”: TTS speech generated and spoken in real time. More recently, with many customer implementations taking the form of AI driven dialog – ‘real time’ has assumed even more importance. For how can you have a conversation if your counterpart takes unnaturally long to respond?
Part of the challenge is that the text to be spoken can be lengthy, and generating TTS audio takes time. The longer the text, the more time required. We address this problem by slicing the text into segments, processing them in parallel, and seamlessly speaking them in sequence. This is done automatically & transparently. The first segment is always the shortest, to minimize initial response time. Subsequent segments are progressively longer, as we process them while the avatar is already speaking.
Recently we’ve gone a step further, allowing users to fine-tune the process. You now have the option to select the optimization level you prefer. There is a balance to be had though, because more segments means more stream usage.
Three optimization levels are provided. ‘Normal’ – which is the mid-level choice – is the default, and should be appropriate for most implementations. If you are using our 3rd party TTS voices tough, in particular Eleven Labs or Open AI voices, you may want to select the ‘High’ optimization setting. These providers require a bit more time to generate audios, especially longer ones (though improvements are being made all the time and this statement may not be true a few months hence).
Already mentioned above, but worth repeating, is that the length of the text is a major factor determining the time required to generate the audio. And the impact of the length of the text on response times is greater with some engines than with others.
The ‘High’ optimization setting improves the initial response time by segmenting the text input more aggressively. Specifically – the first segment becomes very short, and subsequent (longer) segments are also correspondingly shorter to allow for seamless playback.
But, as with all things, there is no free lunch. We mentioned that more segments mean a higher stream usage. But there is another caveat. Ideally, we prefer to break our audio segments at what we call “natural break points” – such as an end of sentence, or a comma. But with a more limited range in which to locate an optimal segment break point – it may not be possible in every case to select a natural one. This may result in a (barely) noticeable segment break in mid sentence.
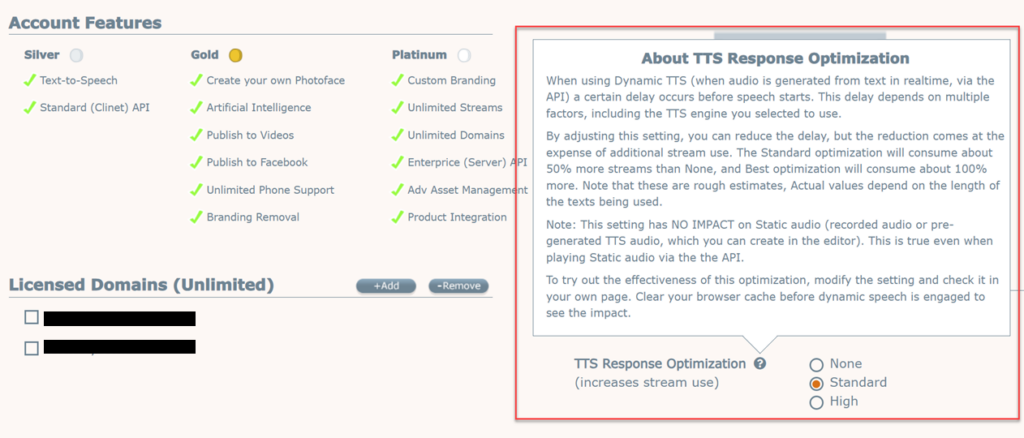
So it’s a tradeoff. The best way to decide is to try. The ‘TTS Response Optimization’ setting can be found in your SitePal Account’s ‘Settings’ page, and it affects all avatars published from your account.
We hope this information proves useful. Please reach out to us with any questions or comments. We’d love to hear from you.
Warm Regards,
The SitePal Team